 |
LigASite database of binding sites |
|
PDB ID and HEADER, TITLE and
COMPND records of the PDB file. | | (click anywhere in this window to remove it) |
|
| 2dhq |
|
|
| 3-DEHYDROQUINATE DEHYDRATASE FROM MYCOBACTERIUM TUBERCULOSIS |
TITLE |
|
|
| PROTEIN (3-DEHYDROQUINATE DEHYDRATASE) |
COMPND |
|
|
|
|
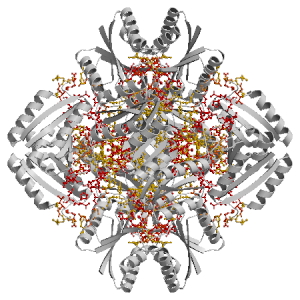
Figure highlighting the binding site residues. Figures were drawn with
Molscript (7) and rendered with
Raster3D (8). PISA coordinates
(3) are used when available
(all entries except NMR). | | (click anywhere in this window to remove it) |
|
 |
|
List of binding site residues detected in this protein. Column 1 gives the position, coloured on a yellow-to-red scale depending on the fraction of corresponding holo-structures where the residue is in contact with a ligand.
Column 2 gives the 3-letter amino acid code, coloured according to physico-chemical type. Chain ID's of residues are not mentioned in this page because all chains in the apo-structure refer to the same protein. | | (click anywhere in this window to remove it) |
|
| 11 | |
PRO |
| 12 | |
ASN |
| 13 | |
LEU |
| 15 | |
ARG |
| 16 | |
LEU |
| 17 | |
GLY |
| 18 | |
ARG |
| 19 | |
ARG |
| 20 | |
GLU |
| 24 | |
TYR |
| 25 | |
GLY |
| 63 | |
HIS |
| 75 | |
ASN |
| 77 | |
GLY |
| 78 | |
GLY |
| | 81 | |
HIS |
| 84 | |
VAL |
| 87 | |
ARG |
| 88 | |
ASP |
| 89 | |
ALA |
| 91 | |
ALA |
| 92 | |
GLU |
| 101 | |
HIS |
| 102 | |
ILE |
| 103 | |
SER |
| 105 | |
VAL |
| 106 | |
HIS |
| 108 | |
ARG |
| 109 | |
GLU |
| 110 | |
GLU |
| | 111 | |
PHE |
| 112 | |
ARG |
| 113 | |
ARG |
| 114 | |
HIS |
| 115 | |
SER |
| 116 | |
TYR |
| 118 | |
SER |
| 119 | |
PRO |
|
|
|
| PDB |
The Protein Data Bank |
| CSA |
Catalytic Site Atlas |
| PDBSum |
Overview of the macromolecular structure |
| CATH |
Protein Structure Classification |
| Scop |
Structural Classification of Proteins |
| Pfam |
Protein Families and Domains |
| UniProt |
Universal Protein Resource |
LIGPLOT (only on holo-pages) is hosted at the EBI. The LigPlot Jmol links point directly to the Jmol visualisation interface provided on the PDBSum page. Note that due to different software used, the atomic contacts of LigPlot and LigASite do not necessarily correspond. | | (click anywhere in this window to remove it) |
|
Links to external databases: |
|
Several files are provided for download: | • The XML file defining the residue-ligand contacts; this file contains data on the apo and all holo-structures. |
| • The XML Schema file defining the semantics of the XML file |
| • 3D coordinates of the structure used in constructing LigASite (PISA structure file whenever available, PDB file otherwise. |
| • 3D coordinates of the combined binding residues in the apo structure |
| • 3D coordinates of the binding residues of the holo structure (only on the holo page) |
Coordinate files are in PDB format. | | (click anywhere in this window to remove it) |
|
|
|
|
|
Table describing the holo-structures and ligands used to define
the binding sites.
Column 1 gives the PDB ID of the holo-structure.
Column 2 gives the unique ID of the ligand;
a space-separated list of HET-groups that constitute
the ligand (see Methods).
Each HET-group in the ligand is uniquely identified by
a string in which the first four characters are the three-letter
HET ID from the PDB file followed by the chain ID from
the PISA file, and the last four characters are the residue sequence
number from the PDB file.
Column 3 gives the number of atoms in each ligand.
Column 4 gives the number of protein-ligand inter-atomic
contacts. | | (click anywhere in this window to remove it) |
|
| pdb ID |
Ligand Unique ID |
#atoms |
#contacts |
| 2y77 |
CB8P1144 |
29 |
84 |
Details |
|
CB8R1144 |
29 |
83 |
|
CB8B1144 |
29 |
83 |
|
CB8T1144 |
29 |
83 |
|
CB8V1144 |
29 |
80 |
|
CB8F1144 |
29 |
80 |
|
CB8N1144 |
29 |
80 |
|
CB8X1144 |
29 |
81 |
|
CB8L1144 |
29 |
83 |
|
CB8D1144 |
29 |
81 |
|
CB8H1144 |
29 |
83 |
|
CB8J1144 |
29 |
81 |
| 2xb8 |
SO4P1146 SO4S1148 SO4U1150 |
15 |
89 |
Details |
|
SO4C1148 SO4E1150 SO4Z1146 |
15 |
87 |
|
XNWW1144 |
22 |
92 |
|
SO4A1150 SO4Y1148 SO4V1146 |
15 |
89 |
|
SO4B1146 SO4G1150 SO4E1148 |
15 |
90 |
|
XNWQ1144 |
22 |
92 |
|
SO4L1146 SO4Q1150 SO4O1148 |
15 |
86 |
|
SO4D1146 SO4G1148 SO4I1150 |
15 |
90 |
|
SO4J1146 SO4M1148 SO4O1150 |
15 |
86 |
|
SO4N1146 SO4Q1148 SO4S1150 |
15 |
89 |
|
XNWU1144 |
22 |
94 |
|
XNWG1144 |
22 |
91 |
|
SO4H1146 SO4M1150 SO4K1148 |
15 |
89 |
|
SO4A1148 SO4X1146 SO4C1150 |
15 |
90 |
|
XNWI1144 |
22 |
92 |
|
XNWM1144 |
22 |
94 |
|
SO4R1146 SO4W1150 SO4U1148 |
15 |
90 |
|
XNWA1144 |
22 |
96 |
|
XNWO1144 |
22 |
91 |
|
XNWC1144 |
22 |
96 |
|
SO4F1146 SO4K1150 SO4I1148 |
15 |
87 |
|
XNWK1144 |
22 |
92 |
|
XNWY1144 |
22 |
92 |
|
XNWE1144 |
22 |
92 |
| 1h0s |
FA6H_200 |
14 |
70 |
Details |
|
FA6R_200 |
14 |
70 |
| 2y76 |
CB7J1144 |
33 |
119 |
Details |
|
CB7R1144 |
33 |
120 |
|
CB7L1144 |
33 |
119 |
|
CB7F1144 |
33 |
115 |
|
CB7B1144 |
33 |
116 |
|
CB7X1144 |
33 |
115 |
|
CB7T1144 |
33 |
116 |
|
CB7D1144 |
33 |
118 |
|
CB7H1144 |
33 |
118 |
|
CB7N1144 |
33 |
121 |
|
CB7V1144 |
33 |
120 |
|
CB7P1144 |
33 |
121 |
| 2y71 |
CB6L1144 |
24 |
113 |
Details |
|
CB6V1144 |
24 |
110 |
|
CB6D1144 |
24 |
113 |
|
CB6P1144 |
24 |
109 |
|
CB6B1144 |
24 |
110 |
|
CB6F1144 |
24 |
113 |
|
CB6T1144 |
24 |
108 |
|
CB6J1144 |
24 |
108 |
|
CB6N1144 |
24 |
108 |
|
CB6X1144 |
24 |
113 |
|
CB6R1144 |
24 |
108 |
|
CB6H1144 |
24 |
109 |
|
|
|
|
v9.7
April 2012 |
Interdisciplinary Research Institute, Computational Biology, Villeneuve d'Ascq, France
University College London, Biomolecular Structure and Modelling Unit, London, UK
Hospital for Sick Children and University of Toronto, Structural Biology and Biochemistry Program, Toronto, Canada |
| Script execution time: 0.1542 seconds |